Lverage is a database repository for Lytechinus variegatus (green sea urchin) predicted DNA binding motif sequences.
Please select one of the following input types and enter a gene to view its corresponding DNA binding motifs.
Lverage is a database repository for L. variegatus predicted DNA binding motifs utilizing ≥70% amino acid identity homology, described by Weiruch et al. 2014, with well-mapped homologous species. The Lverage database includes LvEdge IDs, which link to LvEdge, which stores the sequence and gene expression data for urchin genes for all time points.
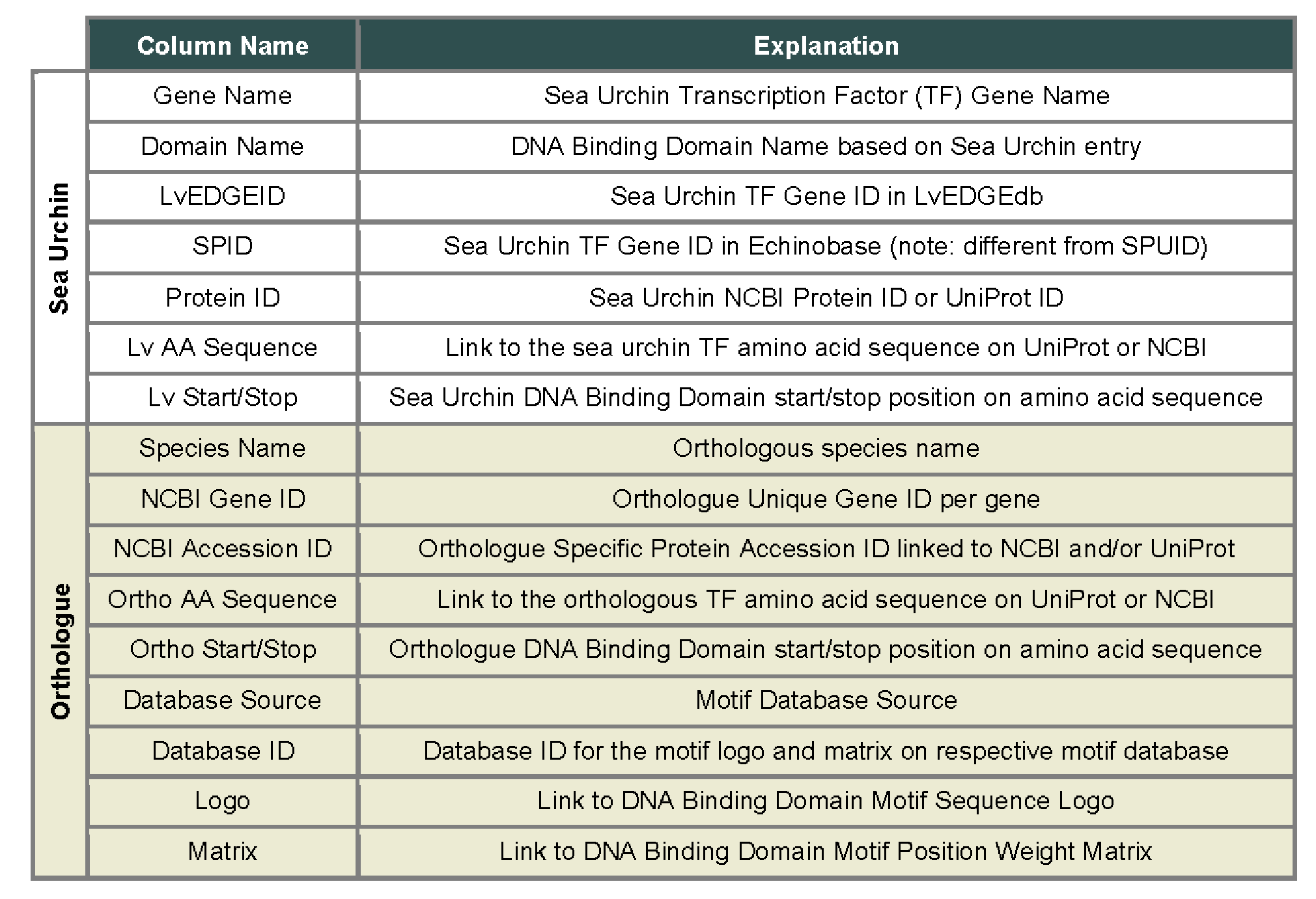
Lverage repository houses motifs specific information from JASPAR, Cis-BP, and HOCOMOCO as well as transcription factor protein specific information from Uniprot and gene level information from NCBI Gene. Additionally, Lverage preserves LvEdge ID searchable in LvEdge and spid (link to about page) searchable in Echinobase. For more information on column specific information, head to the Help page.
This project, conceptualized by Dakota Hawkins, was developed at Boston University for BE768 in Spring 2024, with Gary Benson as the instructor. Lverage was further developed by Stephanie Hao, Yeting Li, Nofal Ouardaoui, and Priyanka Roy and supervised by Cynthia Bradham. The logo was designed by Stephanie Hao.
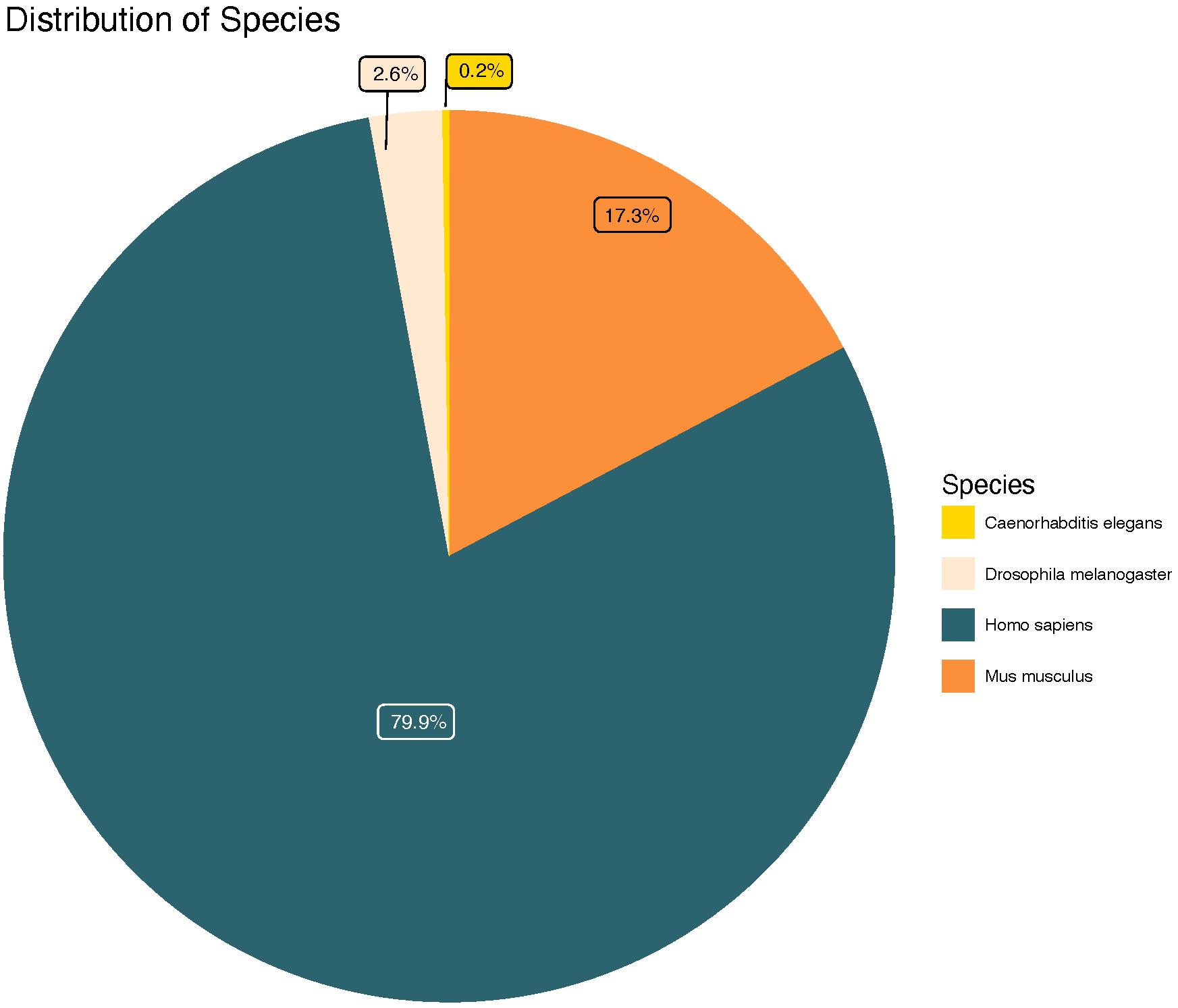
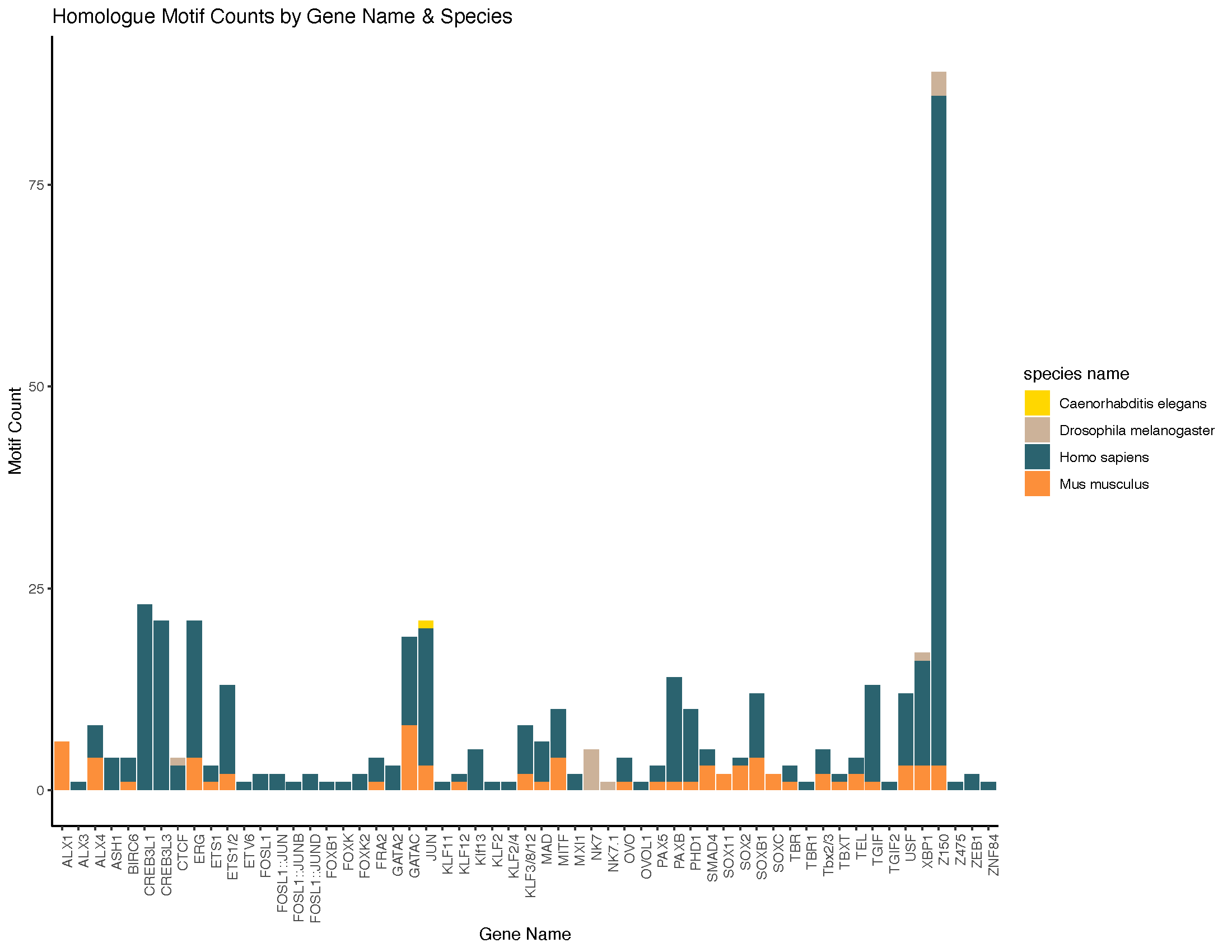
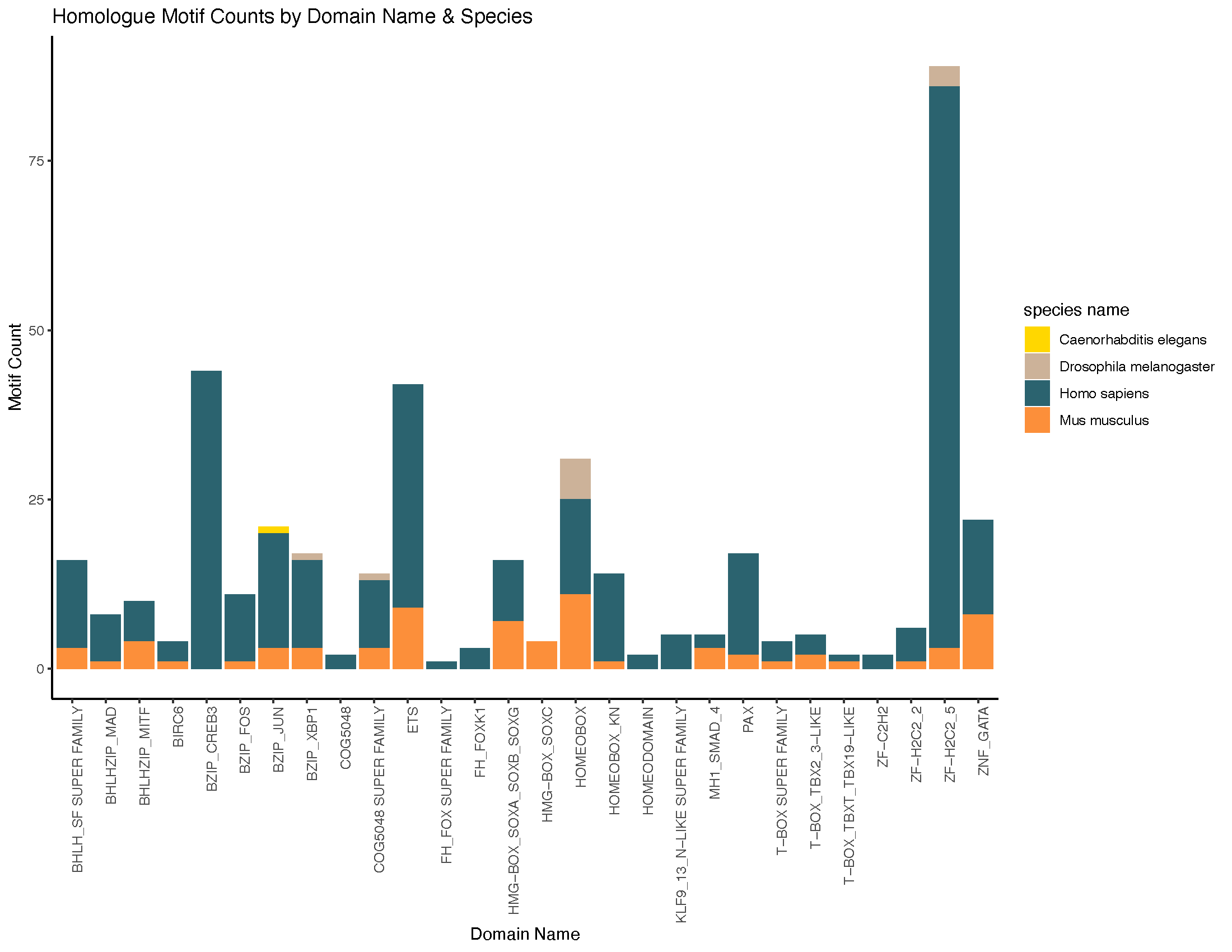
This database provides comprehensive and curated data on L. variegatus predicted DNA binding motifs based on DNA binding domain homology with homologous species. For more information, please check out our About page.
Users can search the database using several criteria, including Gene ID, SP-ID, or LvEDGE ID on the Home page. Our search filter functionality allows for filtering results based on specific parameters to help refine your queries.
Yes, users can download the datatable of a search by pressing the "Download Result" button. The downloaded output is a tab deliminated (.tsv) file. The figures related to the overall composition of the Lverage database on our About page are also downloadable as .png files by pressing the "Download Images" button.
Each transcription factor gene can be associated with multiple motif logos and matrices due to its presence across various homologues. While the Gene IDs might remain the same, each row represents unique combinations of motif logos and matrices, reflecting the diversity of interactions in different contexts.